Fly.io Distributed System Challenge with Go (Part 1)
Recently, I ran into an instresting challenge on distributed systems provided by Fly.io. After going through a laborious semester trying to get in touch with my inner Ninja of theory and implementation, I thought that it would be a good chance to check my understanding of the field.
- Check out my repo for the actual implementation in Go!
Part 1, 2: Echo / Unique ID Generation
These parts were really about familiarizing oneself with the Maelstrom testbench, which the challenge utilizes to abstract basic node-level operations (send, sync/async rpc, etc.).
Globally-Unique ID Generation
There could be a different number of approaches one could take to handle this operation in a distributed setting. My implementation was fairly simple. Given that each of the nodes have their own unique ID, each node will keep its own counter. Then, a unique ID can be easily generated by concatenating the node ID with the counter value, which is incremented on each incoming client request.
func generateID(nodeId string) string {
count++
return nodeId + strconv.Itoa(count)
}
There wasn’t any complicated logic; in fact, the snippet above was pretty much the gist of it.
Part 3: Broadcast
Things began to ramp up from this section, as now the problems required communication between internal nodes, unlike the previous problems which only required exclusive communication between the clients. (Protocol specification available here)
Naive Broadcast
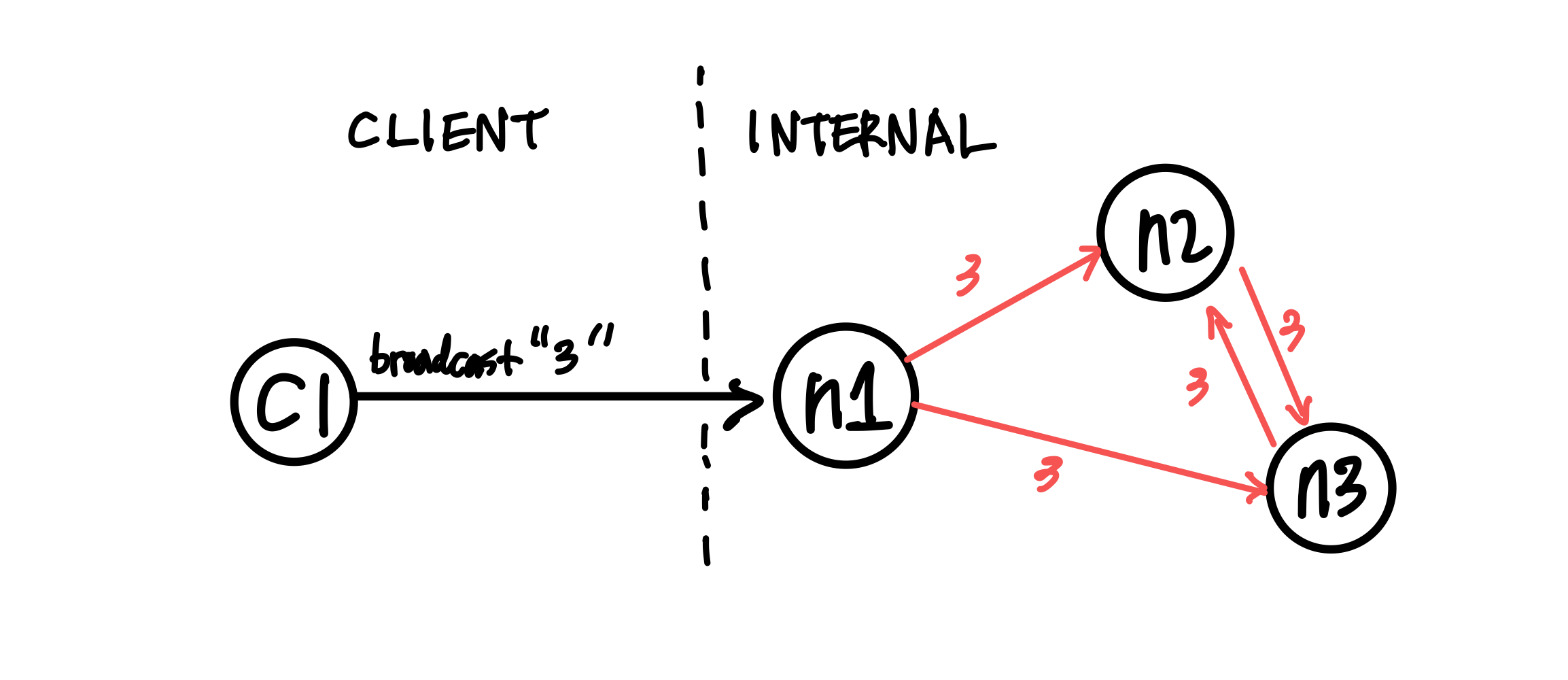
Figure 1: Client sends a request to broadcast “3”
The simplest way (aka the bare minimum) to broadcast a message as a node in a distributed system would be to relay the message to its neighbors whenever a new message is received. The diagram above shows that case: client 1 sends a request to broadcast 3, and node 1, as the initial recipient of tha message, will relay 3 to its neighbors. One thing to be careful when forwarding the message here would be to refrain from sending back the same message to its sender, since that would cause an infinite loop - n1 sends 3 to n2, n2 relays it to n3, n3 to n1 and so on.
Of course, this approach is not efficient at all. Even for a simple network as in the diagram above, we can see that n2 and n3 are receiving duplicate messages. For more complex networks with higher throughput, this will be a major deal breaker. It’s also prone to network failures and site failures, since it is built upon the assumption that the system is fault-free.
Implementing in Go
The idea for this stage was pretty simple, but there were some issues worth considering in the implementation process. In order to check whether a value already has been forwarded (on the receipt of a broadcast request), there should be some sort of a database that keeps all observed (and forwarded) values.
However, a naive hashset (map[int]any) will be problematic. For each node, there will be a main event loop running, waiting for incoming requests. Once a message arrives, a handler for that message will be called in a separate goroutine. This means that the read/write operations to the map is most likely concurrent, which is not allowed for maps in Go. So I created a wrapper for the map, along with its own mutex as below.
type MapStruct[K comparable, V any] struct {
sync.RWMutex
M map[K]V
}
func (m *MapStruct[K, V]) Get(key K) (value V, ok bool) {
m.RLock()
defer m.RUnlock()
value, ok = m.M[key]
return
}
// ...omitted
This resolved the concurrent map read/write issue, and when run on a system of 5 nodes with a load of 10 messages/sec, showed a message-per-op value of 10.14, meaning that it took approximately 10 messages internally to broadcast. However, when everything scaled up (25 nodes, 100 messages/sec), the message-per-op value grew to 75.6. Not particularly impressive, but the test run showed that the broadcast protocol is in fact functional.
Partition Tolerance
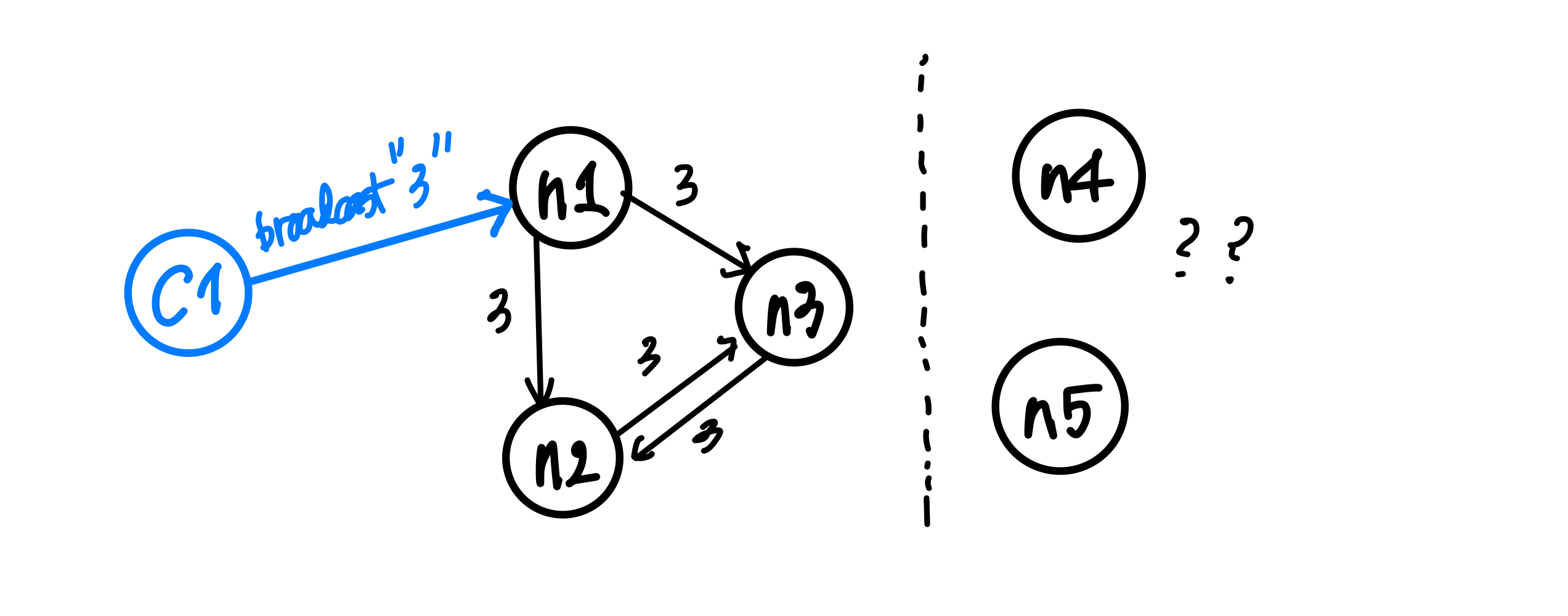
Figure 2: Broadcasting in the presence of a network partition
There could be all kinds of nemesis a distributed system may encounter, and network partition is definitely one of them. A network partition1 happens when the operational nodes are divided into networks of two or more fully-connected components (cliques), and communication between those components are disabled. The previously designed system will be unable to survive this failure, as it only relays messages to its neighbors once. If the neighbor was partitioned during the arrival of a new message, it won’t ever be sent again, breaking consistency between different nodes across the partition.
How could we build a system that is eventually consistent in the presence of such failures? There may be different ways to address this issue, but retries could be a solution. Instead of mindlessly throwing values at one’s neighbors upon the receipt of a new message, it could expect an acknowledgement from each neighbor to make sure that it received the value. That way, the nodes will keep trying to reach the neighbors on the other side of the partition, and ultimately to sync up on the values when the partition heals.
Implementation in Go
For each incoming message, the broadcast message handler now made use of the RPC() call, which comes with its own handler to process the ACK message returned by its neighbor. When a broadcast request for a new value arrives, a node will do the following:
- Create a map of neighbors (
waiting) to relay the broadcast and expect an ACK from - Retry the relay RPC (only for those that haven’t returned an ACK yet) until all recipients sends back an ACK
Although the logic wasn’t that complicated, it was tricky to evade the concurrent read/write issue for the waiting map, especially since it had to iterate over each key/values. I could’ve dealed with this issue by placing mutex locks, but decided to check out the sync.Map provided by Go, which seems to be recommended for a limited use case (stated below) over the traditional Go Map paired with mutexes:
- When the entry for a given key is only ever written once but read many times, as in caches that only grow
- When multiple goroutines read, write, and overwrite entries for disjoint sets of keys.
Since my use case perfectly fit the first one, I decided to track the ACK message receipt progress with it, as in the code snippet below:
// Excerpt from the broadcast handler logic
db.Put(message, nil)
waiting := sync.Map{} // map[string]bool (neighbor addr: is ACK arrived)
for _, neighbor := range neighbors {
if neighbor == msg.Src {
continue // Exclude sender from message relay recipient
}
waiting.Store(neighbor, false)
}
pending := true
var err error
for pending {
pending = false
waiting.Range(func(neighbor, value any) bool {
if v, _ := waiting.Load(neighbor); v.(bool) {
return true
}
pending = true
// Does not block (asynchronous call)
err = n.RPC(neighbor.(string), body, func(msg maelstrom.Message) error {
waiting.Store(neighbor, true)
return nil
})
return err == nil
})
time.Sleep(time.Millisecond * 500)
}
if err != nil { return err }
// ...omitted
After making the change above, the system was able to synchronize itself after the healing of a network partition. It still wasn’t an efficient system overall (55 message-per-op , median/maximum latency of 460, 793ms), but that wasn’t the ultimate objective for this part.
On my next post, I’ll go through how I made the system to become more competent!
Adopted from P.Bernstein, N.Goodman and V.HAdzilakos, Distributed Recovery ↩︎